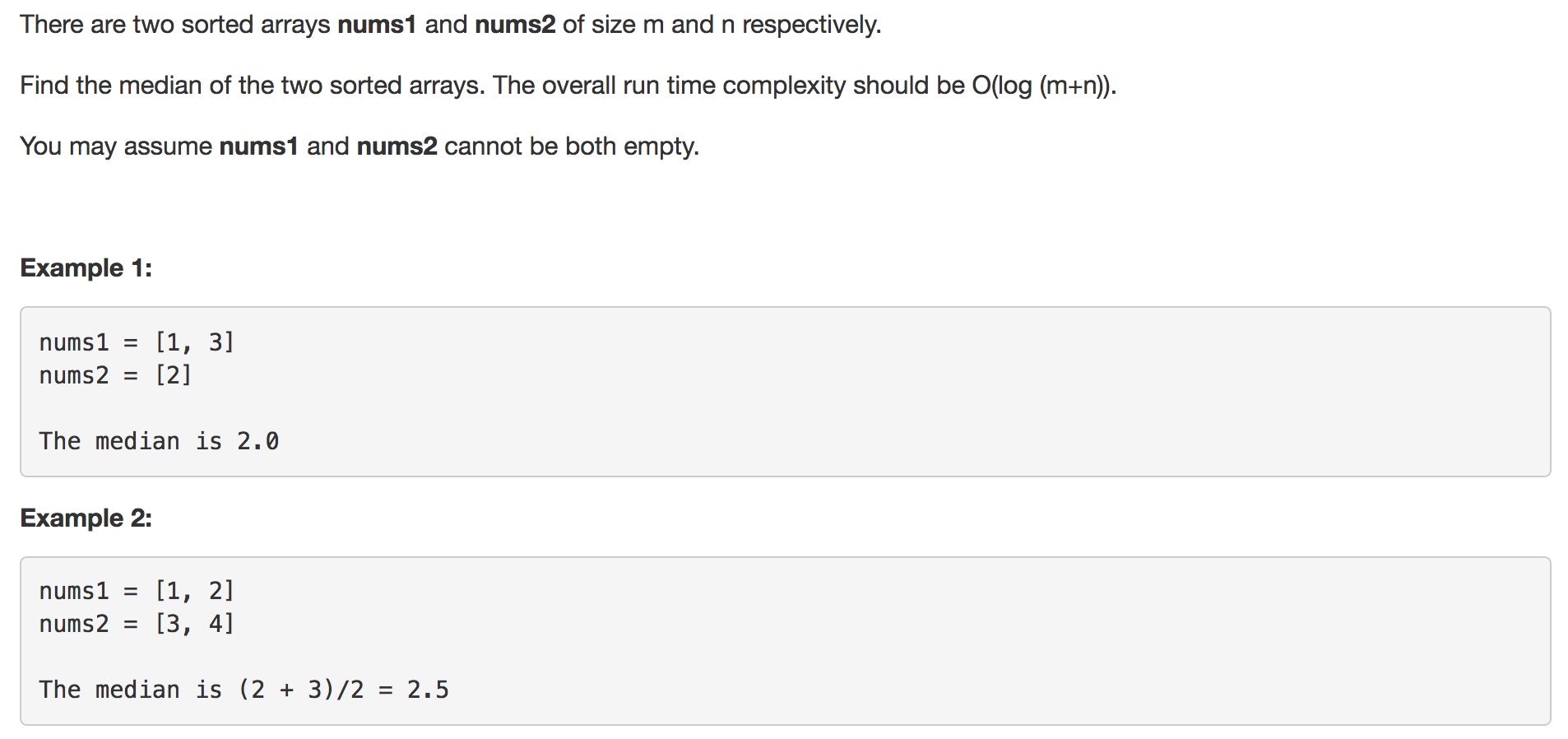
前言
学数据结构的时候,就没有真正的手写过快排,思想是简单,但是算法思想和实现上,还是有一定的差距的,这中间的差距,可能就是所谓的编程能力吧。
这里整理下快排的实现,包括递归方式,非递归方式,pivot不同选取方式等的实现。
基本思想
基本思想描述起来还是很简单的,找到一个pivot元素,每趟把所有元素中,小于的放到左边,大于的放到右边,然后递归的进行就好了。
具体怎么放,就是两边向中间扫,碰到不合适的,就swap。
实现
递归实现
这里pivot选取的是第一个元素
|
|
|
|
这里其实还是很精巧的,简洁对称,在partition的while循环中。
两个while,让l和r运作到指定的位置,但两者并不是同时到达,然后进行swap,而是利用a[0]当做pivot之后,位置空出,正好借此达成互换的目的:先把a[r]放到原来pivot的位置,然后把a[l]放到上一步的a[r]位置,这样,a[l]再一次空出,可以重复这个过程。
非递归实现
非递归的实现,主要是分治的时候,记录当前的l,r位置,这里用栈来存储:
|
|
pivot选取非0位置元素
这里不讨论如何选取这个pivot,有各种选取方式,什么第一个,最后一个,中间的,三个里边的中间值,随机选等等。
其实这些都是大同小异,只不过,上边用a[0]的时候,有一些小trick,如果用其它的话,就不能用哪个trick了,这里自己再单独实现以下。
啊,我好傻啊,干嘛那么想不开,既然不是第一个,换到第一个就对了嘛,还想那么多干嘛…
|
|
算了,权当是,学习一下modern c++中,随机数的用法吧hhh