This post describes all stuffs about my GSoC 2019 project. Including information of my project, what I’ve done, what I’ve learned and how I feel during this program.
Project Information
- Project Title: Edge Animations for Large-Scale Network Graphs
- Student: Xiaodong Zhao
- Organization: Computational Biology @ University of Nebraska-Lincoln
- Mentors: Ales Saska, Resa Helikar
- Project Code Repository: https://github.com/HelikarLab/ccNetViz
Project Overview
My main job is to add more features for ccNetViz library, a JavaScript library for visualization of large-scale network graphs using WebGL. It enables custom styling of nodes and edges in CSS like wavy, curve edges, dynamic changes of the network, force-directed layout and basic graph interactivity. Used for example by Cell Collective project.
As I wrote in my proposal, I’ll add edge animations on it. Including color animations, speed control and other fancy animations like wavy curve, dotted line and bubble flow effects. These animations will be totally customizable and we’ll also offer some high quality presets for user to choose. Finally, documentation for edge animation will be complete and we’ll also have some demo pages to show all effects of edge animation.
Besides, during the process of development, we found the source code need refactoring. So I also done some refactoring job to get it clearer and easier to understand.
Contribution to Project
Commits & Pull Requests
In ccNetViz project, I created:
- 23 Pull Requests. (22 of them were merged)
- 92 commits at main project and 14 commits at ccNetViz’s GitHub Pages project
All these pull requests and commits including:
- Animation features addition: including color animation, shape animation and easing effects.
- Examples for added features: example pages to demonstrate what new features look like.
- Refactoring of code: including code splitting and plugin architecture.
- Documentations: documentation for both animation features and plugin usage.
These contributions will be introduced in detail below.
Detail of Results
1. Edge Animation
The original ccNetViz only support static graph without change over time. I added several animation effects on graph edge so it can convey more semantic information like signal transmission in neural networks or blood flow in blood circulation system.
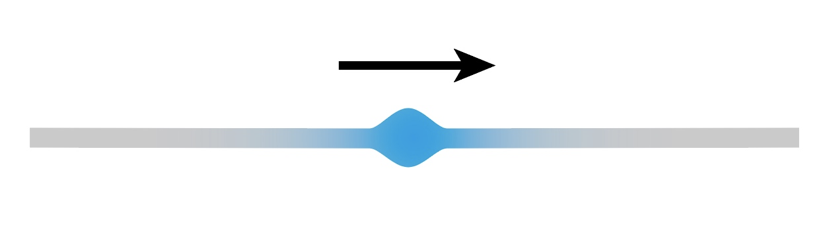
Color Animation
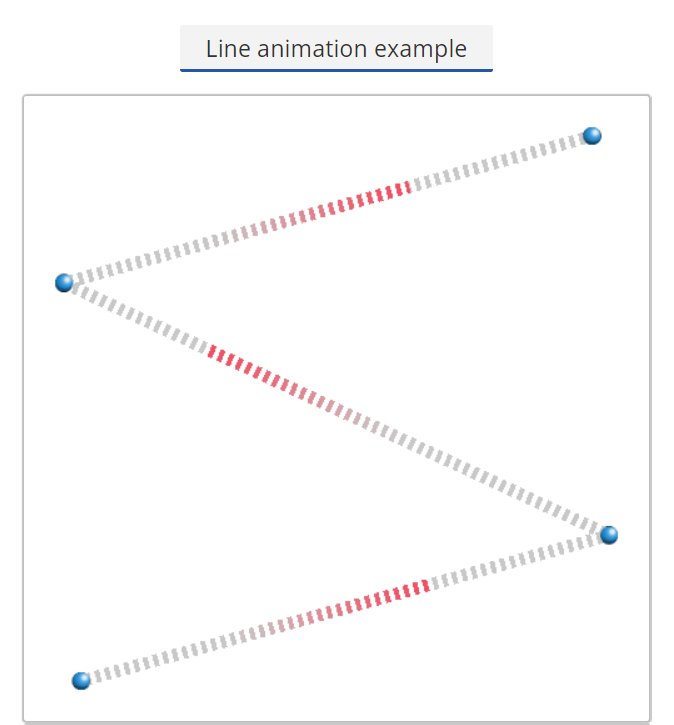
Basic idea of animation is using different color on edge. I implement three type of color animation:
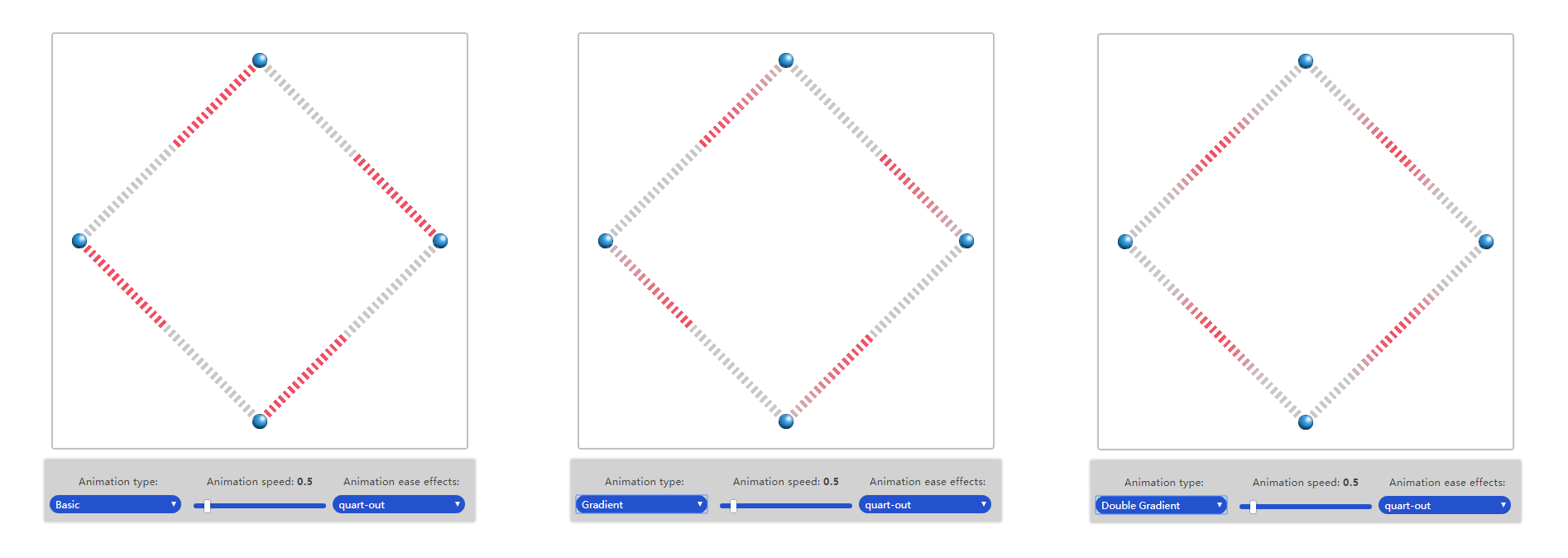
(The above example of color animation can be found here:
https://helikarlab.github.io/ccNetViz/examples/line_animate_complex.html
These three types of color animation are implemented in GLSL shader using similar control logic only with different animation color shape. Because animation is added, at entry of drawing we need add a draw loop to refresh canvas.
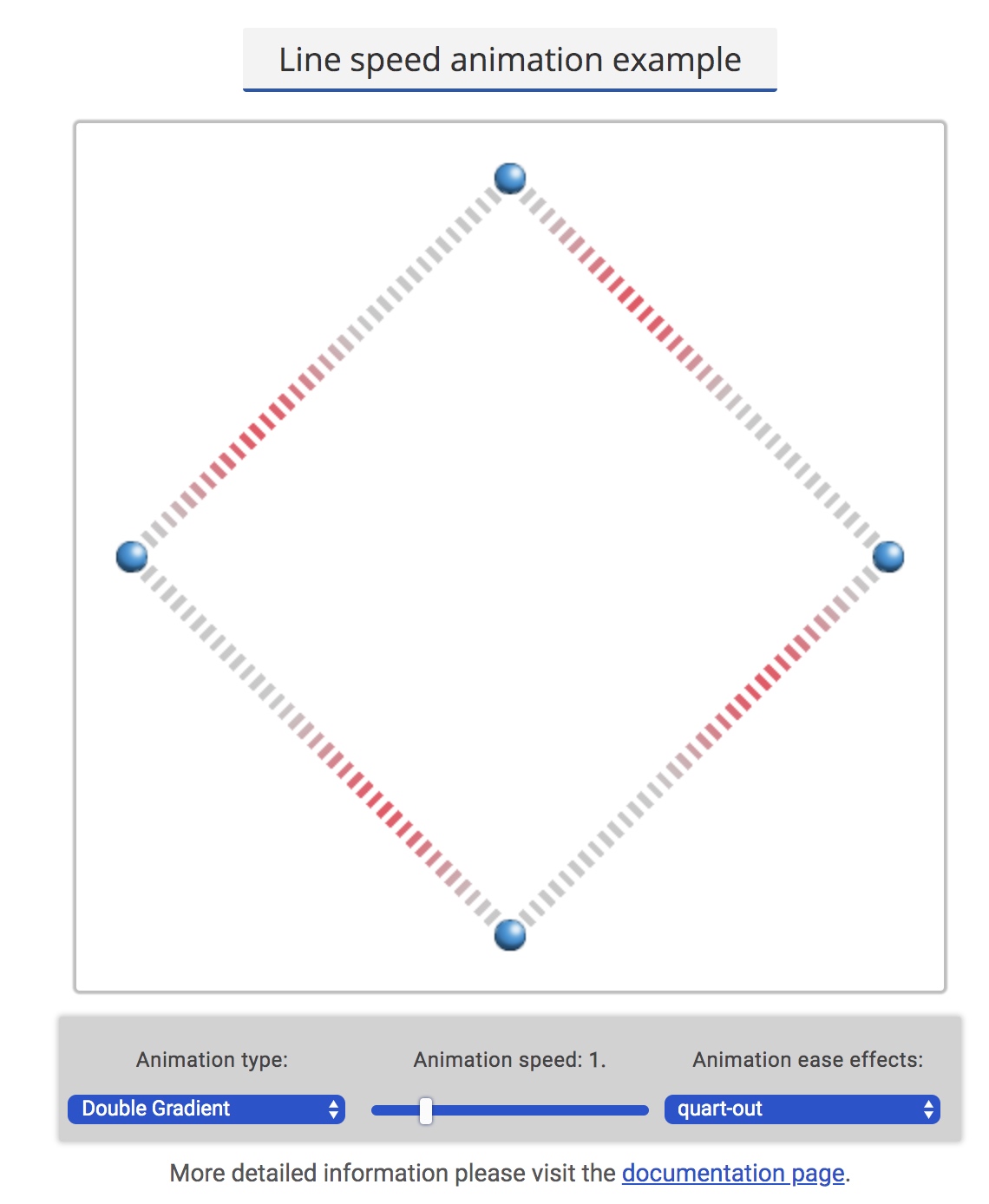
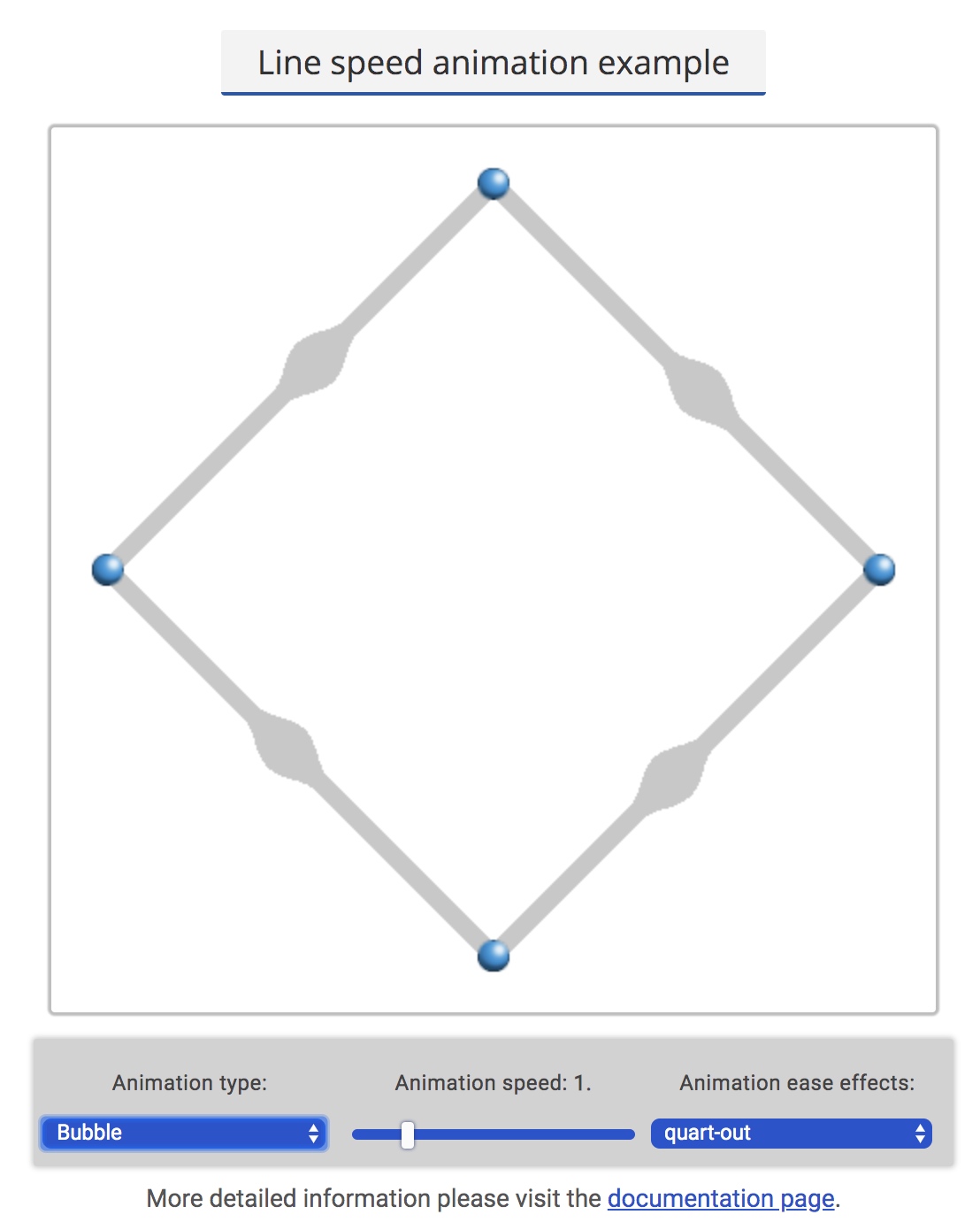
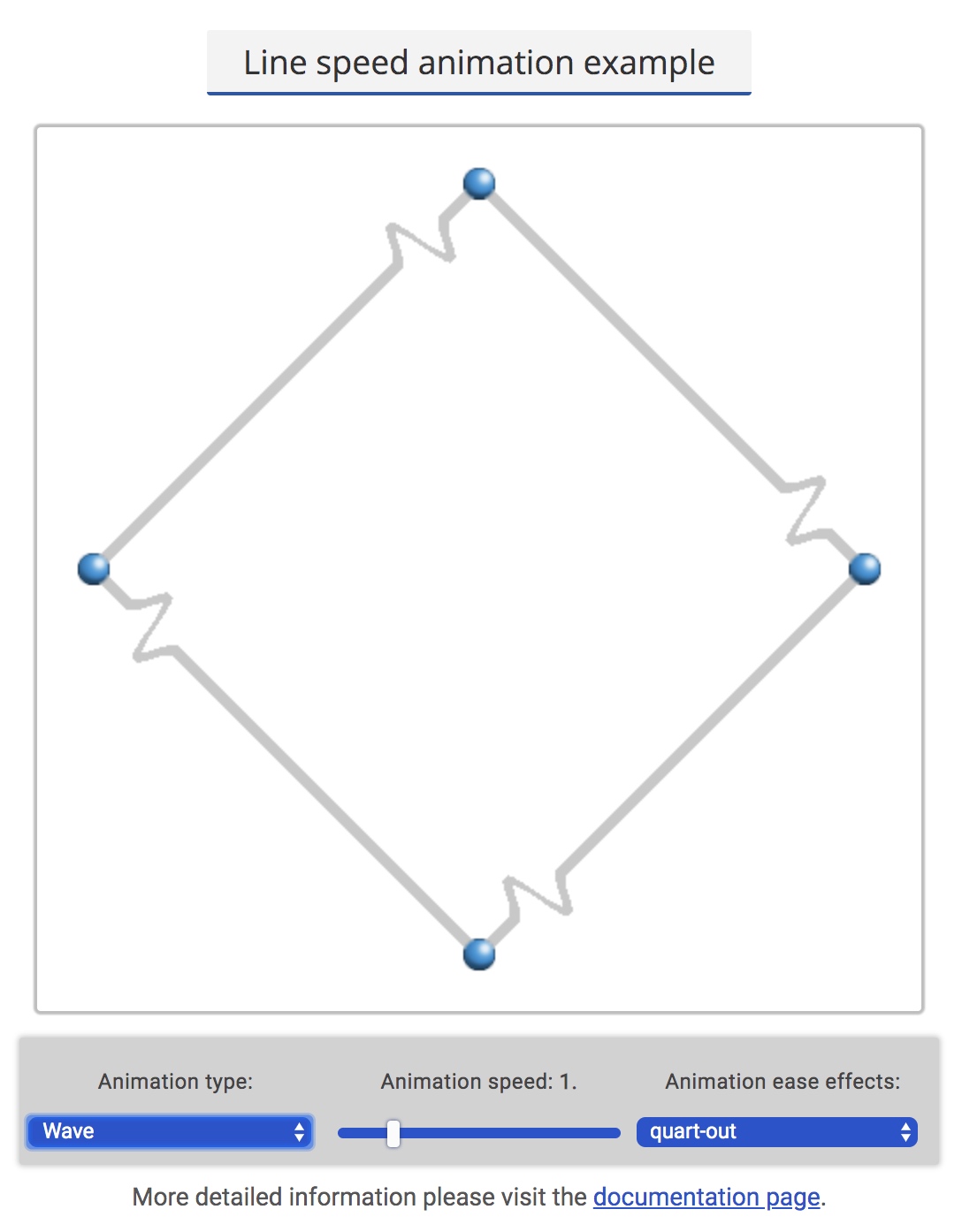
Shape Animation
Shape animation is a kind of more complex animation effects which I implement after color animation. I need to change original shape of edge and show different shapes. Sometimes the shape will show outside of original edge bound, which makes it difficult to implement.
I added three features of shape animation in total, they are: wave effect, bubble effect, dotted effect:
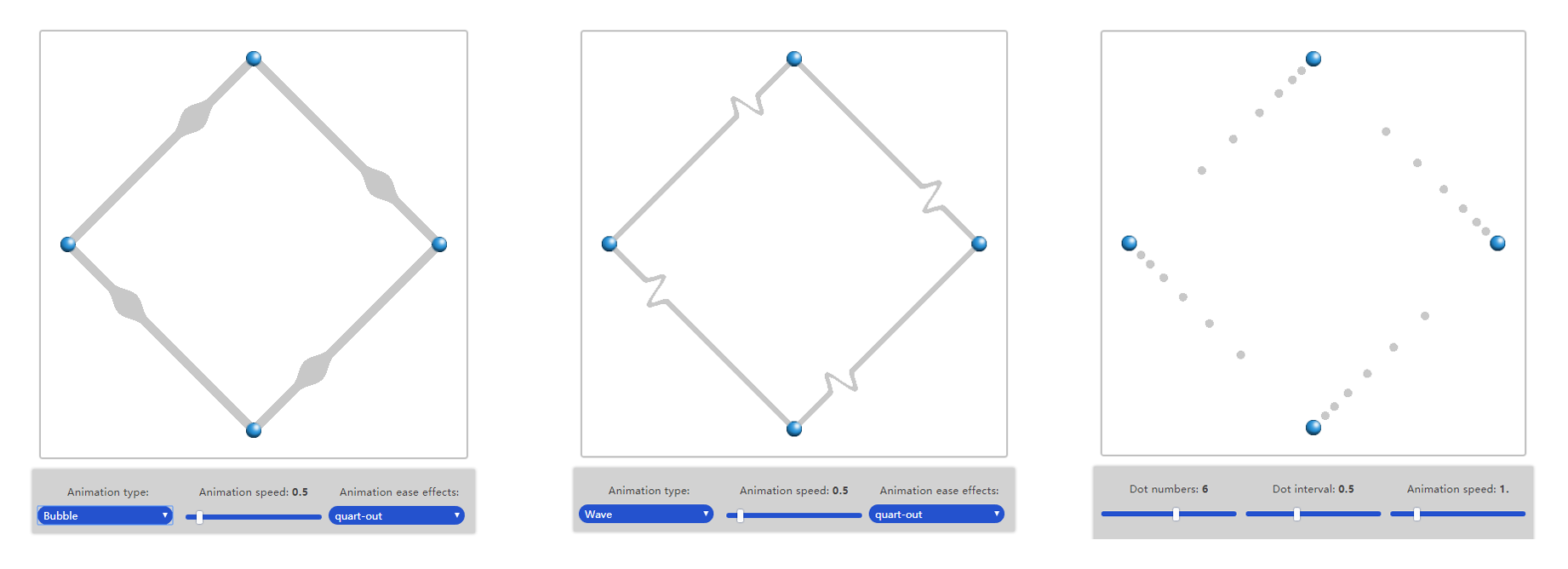
(The above example of shape animation can be found here:
https://helikarlab.github.io/ccNetViz/examples/line_animate_complex.html
https://helikarlab.github.io/ccNetViz/examples/line_animate_dot.html
The options about bubble animation and wave animation are same as color animation, including speed and easing effects. As for dot animation, it also contains other two options to configure: number of dots and interval of dots.
Easing Effects
To enrich the effect of animation, I add easing function on animation speed. According to this website: https://easings.net/en, I add all easing functions on it except from easeBack and easeElastic. Besides, I also add some other easing effects, basically the combination or modification of existing easings: sinInOutInv and quartInOutInv.
All these easing effects can be configured in line advanced animation example.
Benchmarks
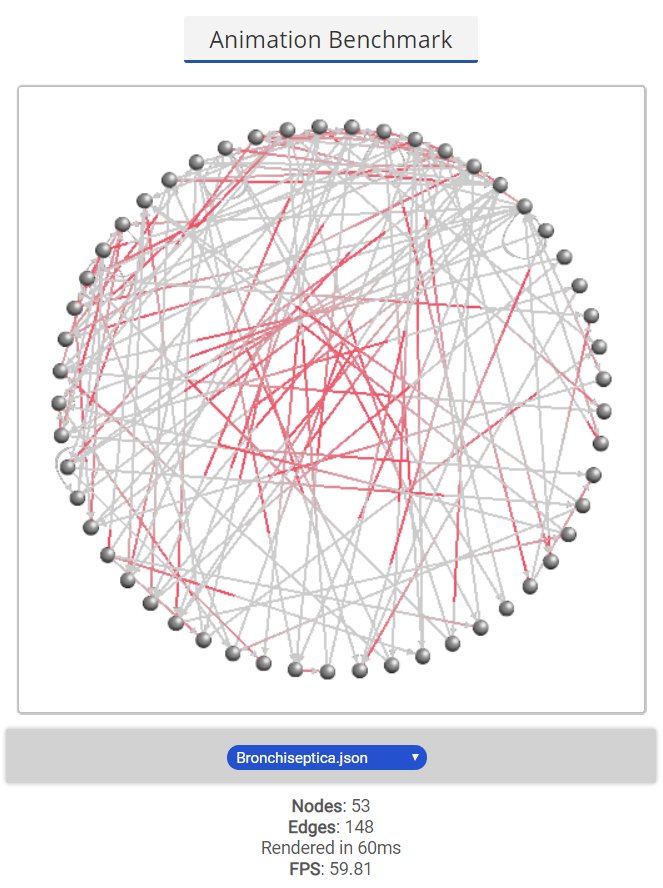
The ccNetViz library is used for large scale graph visualization and the performance is essential when we add new features. So I do some benchmarks on edge animation and calculate its FPS. Below is screenshot of benchmarks:
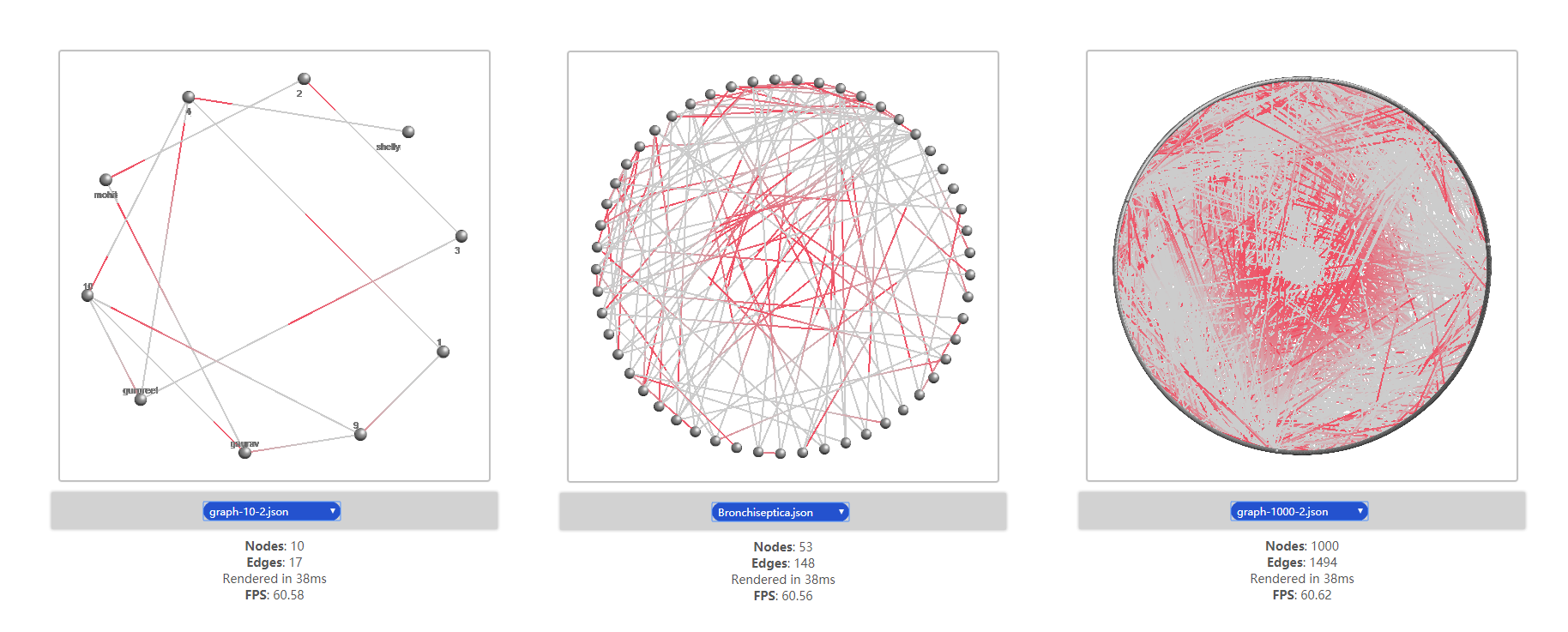
From benchmark results show above, we are inferred that under different scale of graph data, the animation keeps a relative good performance: about 60 FPS.
Examples
To display all effects of new animation features, I add four examples on ccNetViz’s website:
They are:
- basic animation: initial example shows basic and gradient color animation
- advanced animation: shows all animation types except dotted effects and all configurable options
- dotted animation: shows dotted effects as well as its own options
- animation benchmark: benchmark results of edge animation
2. Code Refactoring
In addition to feature implementation, after discussion with my mentor, we found that it’s necessary to do some code refactoring work.
layer.js refactor
To add animation features, the core source code file I needed to understand and modify is layer.js in original code. But it contains more than one thousand lines. I spent a lot of time analyzing this file and added animation logic. Unfortunately, this made layer.js even bigger. One reason was that in ccNetViz, all elements like node, edge, label, arrow, were putted in layer.js together. When someone wanted to add any feature, it would extend this file.
The first ting I needed to do is to move GLSL shader code into separate files, because in original code it used concatenation of strings and made code long and hard to modify. I extracted all stings into .glsl files and use webpack’s raw-loader to load them.
Then I needed to do is to split different kinds of element into different files respectively. This step was hardest part during the who process. There were plenty of dependencies between each other. Finally, code related to same shape was put into same folder and the whole structure got clearer.
Finally, I also rearranged shader files and put them under shape’s folder respectively. After these steps, The original long and obscure layer.js no longer exist and is replaced by clear folder structure of several kinds of shapes.
Plugin architecture
When I was implementing animation features, I added a lot of codes to support new features, which made the size of whole library much larger. To keep ccNetViz lightweight, we finally decided to move animation features outside as a plugin so that it can be imported on demand.
I created a new webpack project and moved shaders of animation functions, easing functions as well as animation logic into it. And all these codes were combined as a new type of plugin: AnimationEdgePlugin and could be easily injected into original ccNetViz at runtime.
The description and documentation of new added animation plugin can be found here:
https://github.com/HelikarLab/ccNetViz/blob/master/plugins/animation-line/README.md
Things learned from Project
Last three months I have been working on this project and learned a lot during whole process. First of all, as a coding program, it’s a big boost to my programming skills. I only wrote some small demo programs of WebGL. It was my first time to handle a large scale project. And for efficiency consideration, most of my work was to write shader language of WebGL. I got a lot practice on shader programming. The code refactoring process helped me think like an architect of software and trained my code abstraction skills.
Another big benefit for me is that I learned a lot of collaboration and communication skills. I learned how to work with other developers together and contribute on a large project. I got familiar with some tools on GitHub for collaboration like issues, pull requests and code reviews. And at regular meeting every week with my mentor, I also practiced my expression skills to clearly state my problem and my thought.
In a word, I learned a lot from this three month program and these things will benefit me forever during my lifetime as a programmer.
Personal Feelings
This is my first time to attend GSoC, or more generally, this is my first time to do real contribution on open source project, so it’s really an amazing experience. Prior to this, I only opened issues for some projects on GitHub but never committed to them. But last three months I could not believe that I even committed more than 100 times on ccNetViz! It’s very rewarding to do contribution on open source library.
I’m very grateful for my mentor Ales. He helped me a lot during last few months. Every time I got stuck and did not know how to continue, he could always give me some constructive suggestions and got me out of woods. He’s a very nice and patient person. Sometimes I asked some ridiculous questions that I didn’t realize, but he always gave me positive suggestions. Without Ales’ help I could not working on this project smoothly.
Student Information
- Name: Xiaodong Zhao
- Email: zxd.brickmaker@gmail.com
- GitHub: https://github.com/brickmaker
- Website: https://brickmaker.github.io/