所有的基础算法,还是要自己再过一遍才放心。
最小生成树的算法过程,既然是最小,自然是一个贪心的过程。
首先明确的一个性质:最小生成树中,边数 = 点数-1
所以,边数是固定的,算法要做的事,找到合法范围内,权值最小的边。
Prim Algorithm
基本思想
跟Dijkstra很像,维护是否确定known,同时不断更新未知点与已知点集的最短距离,选择距离最短的,加入到已知点集中。
pseudocode:
|
|
CPP实现
用的示例是书本上的:
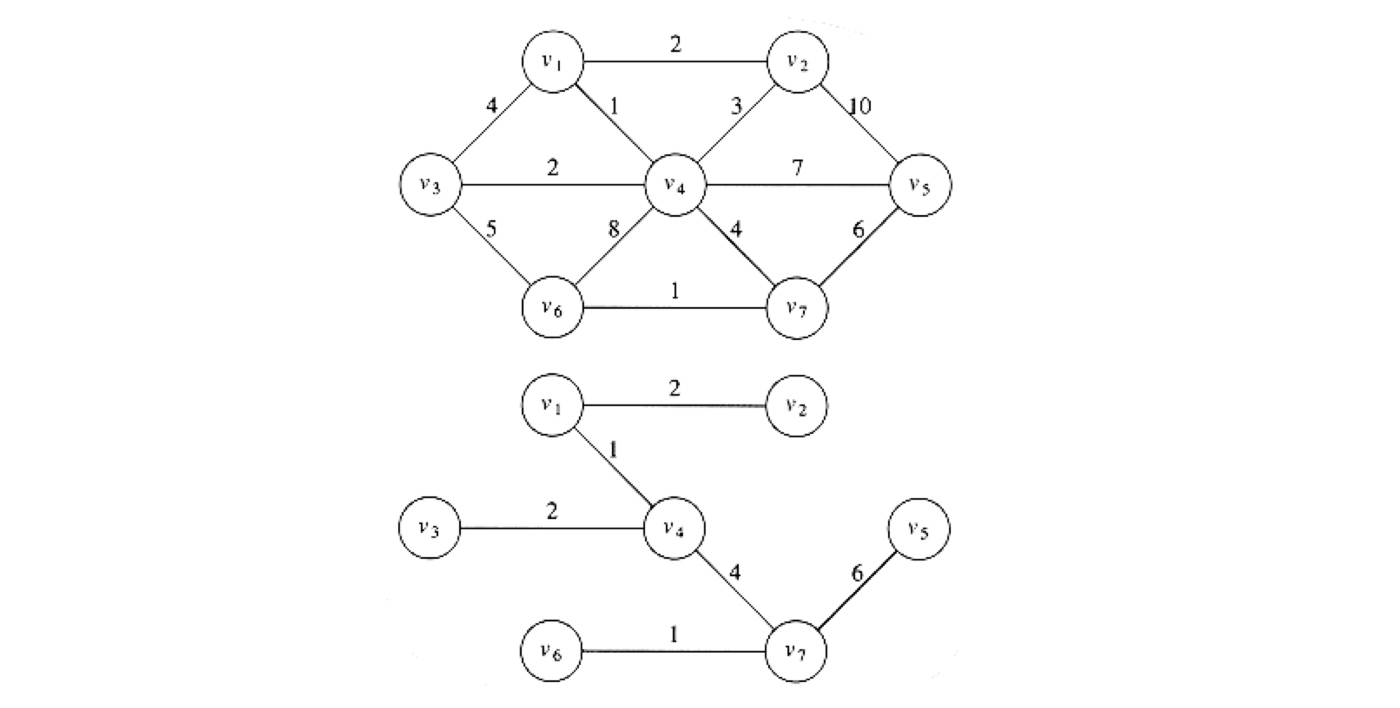
|
|
复杂度
时间复杂度:O( N^2 )
适合边稠密的图,跟稠密程度无关
Kruskal Algorithm
基本思想
不是从点出发,不断加入新的点,而是从边的角度看,不断加入新的合法的weight最小的边
边用堆来维护,这样可以每次取出最小的边
同一颗树内的节点,用并查集来维护,方便判断两个点是不是在一棵树内
从零散的N各点,也就是N棵树出发,找到最小的边,如果边所在的两个点不在一棵树,那么加入这条边,然后合并这两个点集;否则这条边不应该出现在最终的生成树种
实现
|
|
注意CPP标准库中的堆的使用!
复杂度
E次堆的删除操作,O(ElogE)
适合边稀少的图