定义
AVL tree是一个BST对于每一个节点,左子树和右子树的高度差不超过1(空树高度为-1)
这里需要明确,高度的定义:
维基百科:
Height of node
The height of a node is the number of edges on the longest path between that node and a leaf.
Height of tree
The height of a tree is the height of its root node.
树的平衡维护
对一棵平衡的树,进行插入或删除可能改变树的平衡性,这里只考虑插入,删除类似(虽然稍微麻烦一点)。
对于节点X,插入一个节点导致其不平衡,会有四种情况:
- 新增加的节点是其左结点的左子树
- 新增加的节点是其左结点的右子树
- 新增加的节点是其右结点的右子树
- 新增加的节点是其右结点的左子树
后两种情况与前两种镜像,不作考虑,所以是由两种情况,称之为LL(Left-Left)问题和LR(Left-Right)问题
LL
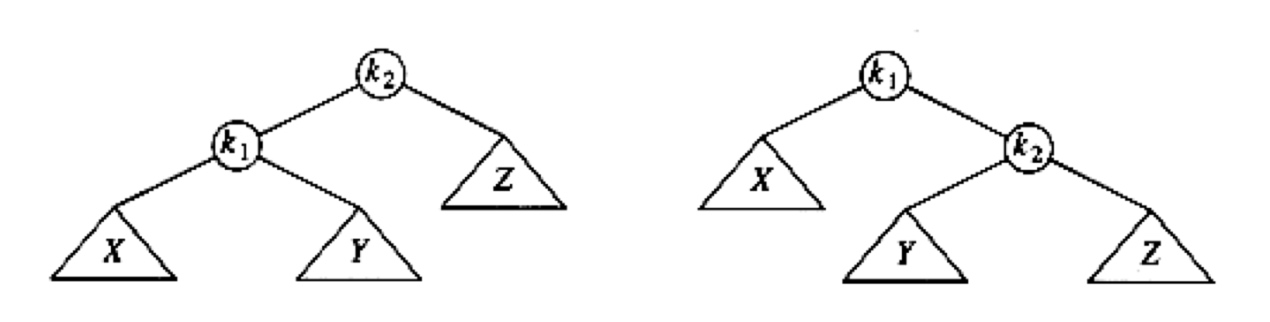
当插入到X,导致$k_1$的的高度 > Z的高度+2的时候,树不平衡!
这时候要做的是想办法,把X提上去,把Z压下来,这里需要做的是从左图到右图的变形,这样的形变也叫做一次旋转。
这里有一个动态演示的网站:https://www.cs.usfca.edu/~galles/visualization/AVLtree.html 显示了旋转的动画效果,非常直观
初始:
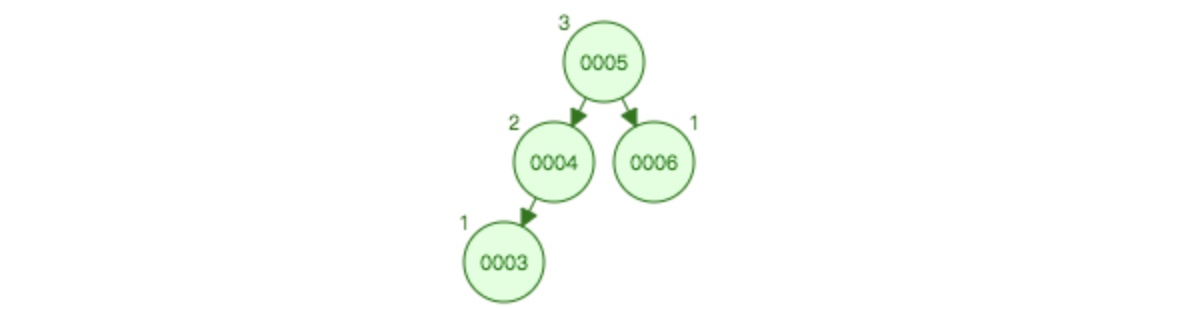
插入2之后:
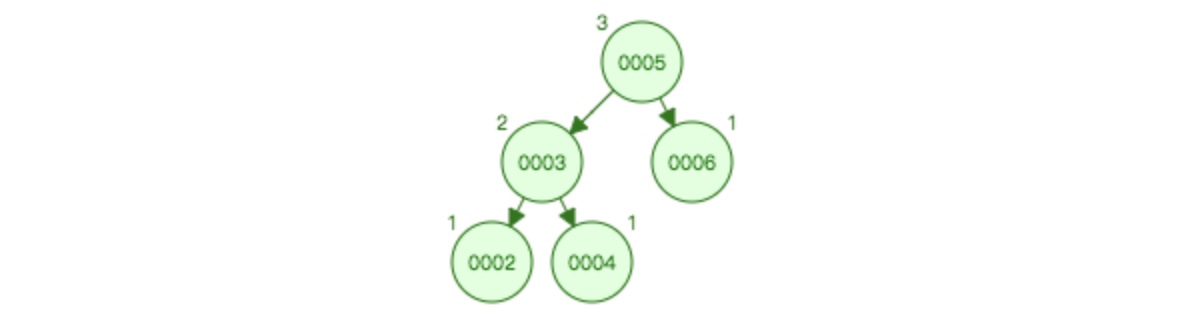
再次插入1之后:
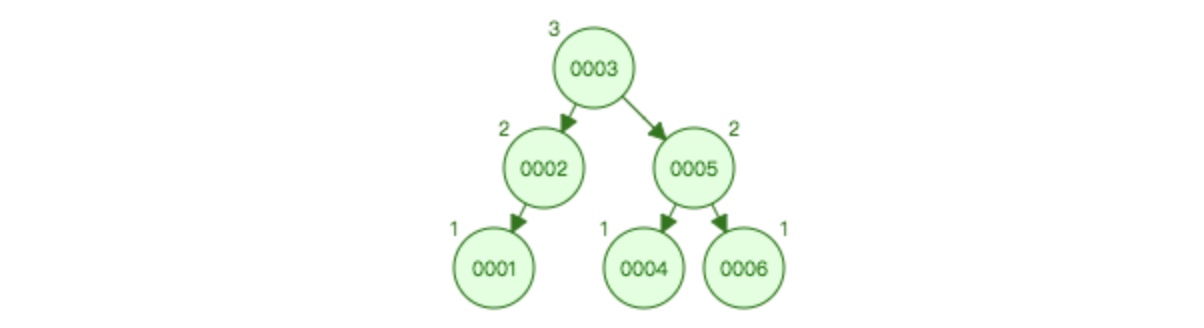
这里树的结构变动比较大,因为不是3结点不平衡,而是根节点5不平衡,所以是5和3旋转,根节点发生改变。
LR
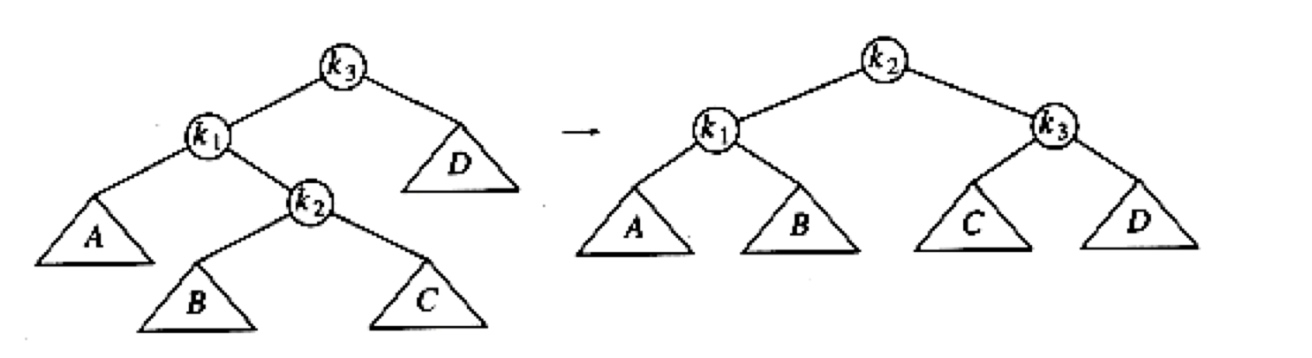
很巧妙的一个变形!
在$k_1$的右子树中插入了东西,导致$k_3$不平衡,现在是要把$k_1$的右子树也就是$k_2$提上去,把D压下去,需要通过两次旋转,就是先$k_1$-$k_2$的一次RR旋转,再$k_2$-$k_3$的一次LL旋转,但是我通常都不想这样记,直接记住这个形式,下边那个从中间“穿过去”,然后原来的左右子树变为新的子树的右左子树。
例子就不举了。
树的平衡化
上述的两个旋转,是平衡化的两个基本操作,平衡化的变形肯定属于这两者。
如果是新的节点插入一棵已经平衡的树的话,用递归的方式非常直观,大概:
|
|
插入操作的实现
PAT-A 1066 Root of AVL Tree
https://pintia.cn/problem-sets/994805342720868352/problems/994805404939173888
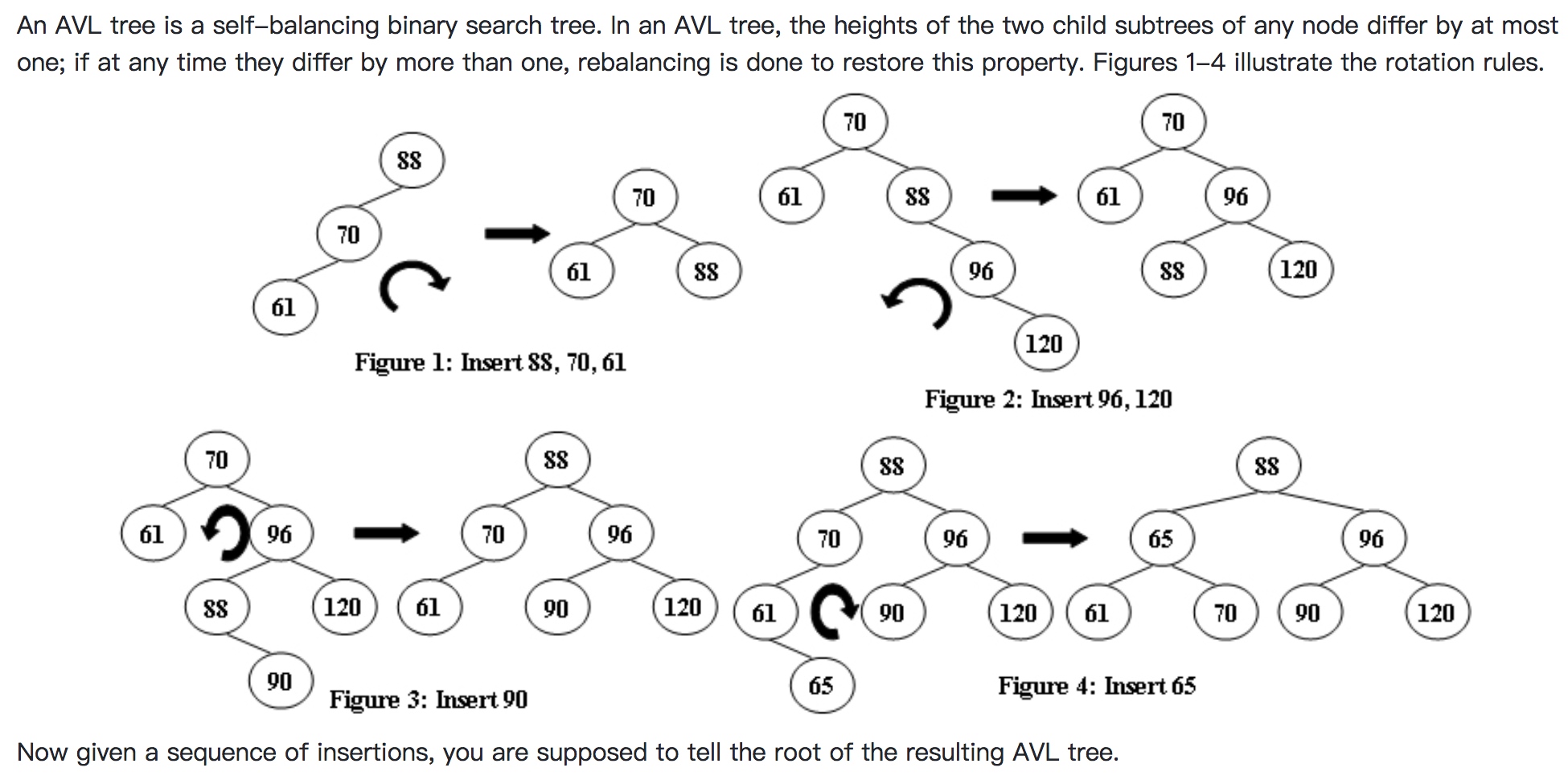
|
|
不要眼高手低啊!!!算法思想,和实现出来,中间的差距,就是你想要提高的所谓的编程能力,或者码力!如果眼高手低,总觉得自己肯定能实现出来,一定会吃亏的!!!